Nếu spider của bạn có số urls khi start_requests quá lớn (>100.000 urls) có thể gây ra các vấn đề về bộ nhớ. Để giải quyết vấn đề này, chúng ta có thể start_requests với số lượng ít url và tiếp tục bổ sung request cho spider về sau.
Table of Contents
Giải pháp
Giải pháp cơ bản là chạy lặp spider mà mỗi lần chỉ thực hiện một số ít các requests. Khi số request trên được thực hiện xong thì sẽ bổ sung thêm request cho spider. Tham khảo sơ đồ dưới đây:
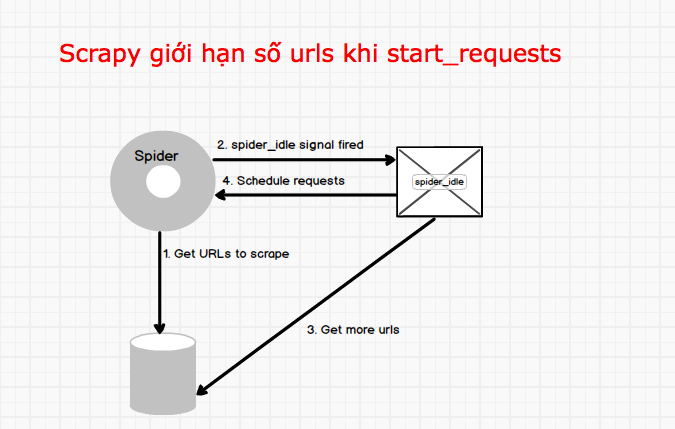
Scrapy cung cấp signal (tín hiệu) spider_idle cho biết khi nào spider rỗi (tức là hết số requests). Khi Scrapy bật tín hiệu này, chúng ta có thể bổ sung thêm số request vào cho spider. Tham khảo spider_idle tại: https://doc.scrapy.org/en/latest/topics/signals.html#spider-idle.
Dưới đây là source code tham khảo
Tạo lớp middleware
Trong project tạo file middleware.py để handle signal spider_idle và bổ sung thêm request cho spider
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from scrapy.exceptions import DontCloseSpider class MySpiderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the spider middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_idle, signal=signals.spider_idle) return s def spider_idle(self, spider): spider.logger.info('===> Spider idle: %s.' % spider.name) spider.logger.info('I am alive. Request more data...') # spider.crawler.engine.crawl(spider.create_more_requests(), spider) reqs = spider.start_requests() if not reqs: return for req in reqs: spider.crawler.engine.schedule(req, spider) raise DontCloseSpider |
Spider sử dụng middleware vừa tạo
Trong Spider chúng ta định nghĩa làm start_requests mà thực hiện giới hạn số request. Mã nguồn như dưới đây:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from scrapy.http import Request class EtuanNVSpider(scrapy.Spider): name = "etuannv_spd" # Config custom setting custom_settings = { 'DOWNLOADER_MIDDLEWARES': { 'datascraper.middlewares.MySpiderMiddleware': 100, }, } def start_requests(self): """Start request data. """ urls = readUrlFromSomewhere(10) # Đây là hàm để đọc giới hạn số url (trong trường hợp này là 10) for url in urls: yield Request( url, callback=self.parse_url, ) |
Trong đó, hàm readUrlFromSomewhere là do bạn tự định nghĩa để bổ sung số urls vào cho hàm start_requests.
Như vậy, với cách trên, chúng ta có thể giải quyết được vấn đề khi số lượng start_requests quá lớn. Chúng ta cũng có thể sử dụng giải pháp này để chạy 1 spider mãi mãi nhằm cập nhật trạng thái của dữ liệu.
Chúc các bạn thành công !

Mình là một lập trình viên tự do với hơn 10 năm kinh nghiệm. Mình chuyên về Web scraping, Web automation, Python, Django